
English
A position statement on CXR report generation has recently been released by the Korean Society of Thoracic Radiology (KSTR).
In summary, positive consensus was achieved only for two questions in the context of health screening:
Q1. How would you rate the reliability of the AI-based automated report-drafting tool?
Q4. Is use appropriate in hospitals with radiologists, provided each report is validated by a radiologist?
For all other clinical settings and all remaining questions, no positive consensus was reached.
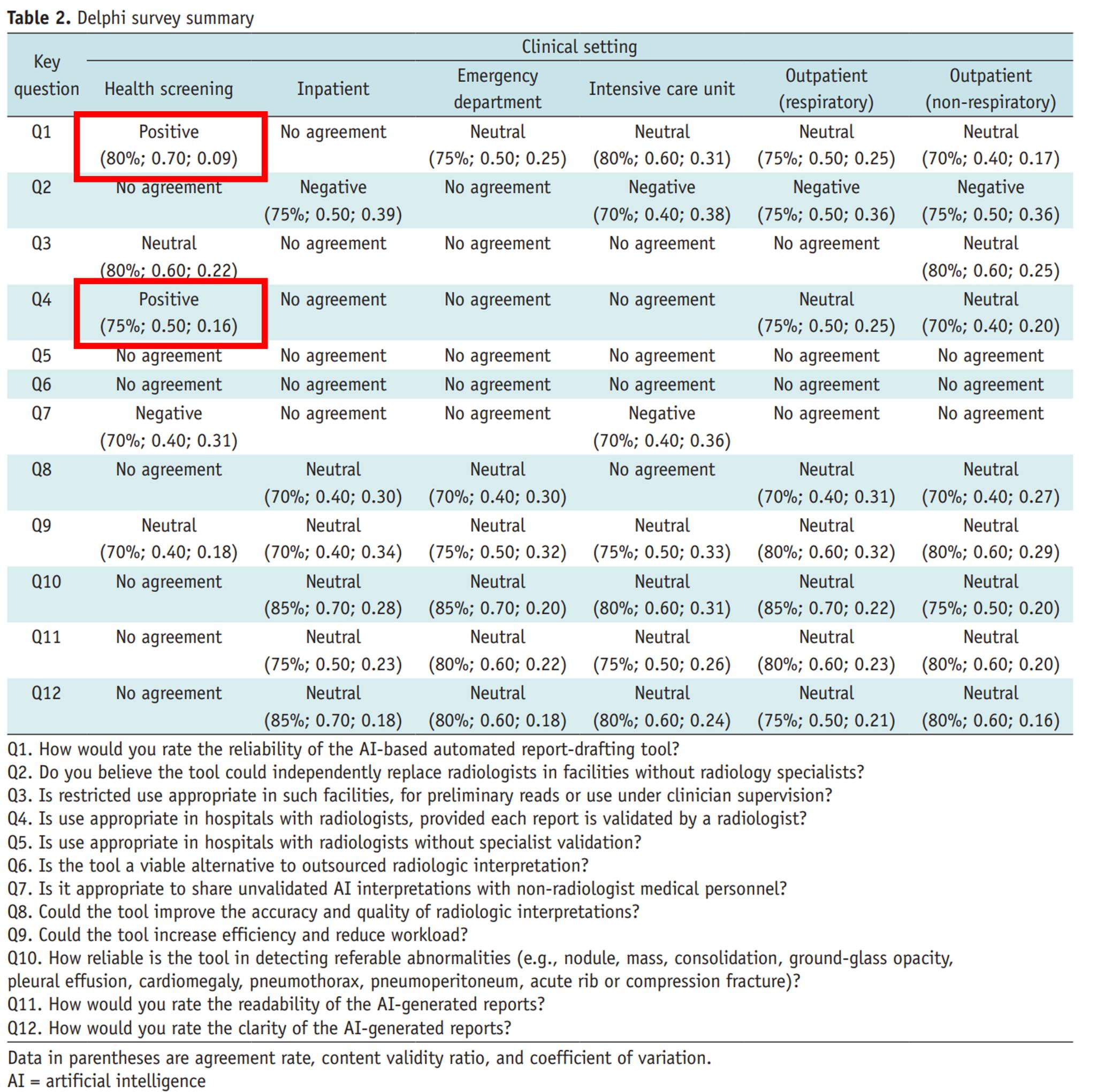
In this position paper, 20 thoracic radiologists evaluated 60 chest radiographs from their own institutions, using KakaoBrain’s KARA-CXR and Soombit.ai’s AIRead-CXR, across six clinical settings: health screening, inpatient wards, emergency rooms, intensive care units, respiratory outpatient clinics, and non-respiratory outpatient clinics.
In the health screening setting, the systems demonstrated a relatively strong performance, with an accuracy of approximately 86%.
However, in all other settings, performance dropped to 60–69%, representing a rather ambiguous and insufficient level of accuracy.
Because detailed breakdowns were not fully provided, it is unclear whether the low disease prevalence in screening populations contributed to the higher performance. Nevertheless, the paper confirms a cautious position: in health screening, AI-based report drafting tools may be acceptable when used under radiologist supervision.
From the perspective of someone who is cautious—or even skeptical—about the use of medical LLMs, it is reassuring to see that the KSTR has articulated what feels like a reasonable and expected stance.
Turning briefly to the U.S. context:
Even though three years have passed since the emergence of ChatGPT, not a single LLM has received FDA clearance or approval as a medical device.
To obtain FDA authorization as a medical device, two critical requirements must be met:
Indications for Use (IfU) - A device must have a clearly defined intended use—for example, stroke detection software or a cardiac pacemaker. LLMs, by design, are general-purpose systems applicable to virtually any domain. As a result, their IfU is inherently ambiguous, which means that under current U.S. medical device regulations, they either: fail to qualify as medical devices at all, or are forced into narrowly constrained indications that undermine their core strengths.
Performance Validation - Generative models produce free-text outputs (e.g., radiology reports), yet there is no established evaluation framework to rigorously validate such outputs. Should a report be considered 100% accurate only if it matches a radiologist’s wording exactly? Or is identifying all clinically significant findings sufficient? Should normal variants also be exhaustively described to qualify as “accurate”? At present, there is no consensus metric that adequately answers these questions.
In Korea, DeepNoid’s M4CXR was designated as an Innovative Medical Device, but detailed evaluation reports have not yet been released. Moreover, even the Guidelines for Evaluating Reimbursement of Innovative Medical Technologies—first published in 2019 and revised in 2023—classify report generation as Category A (existing reimbursed technology). In other words, there is no additional reimbursement.

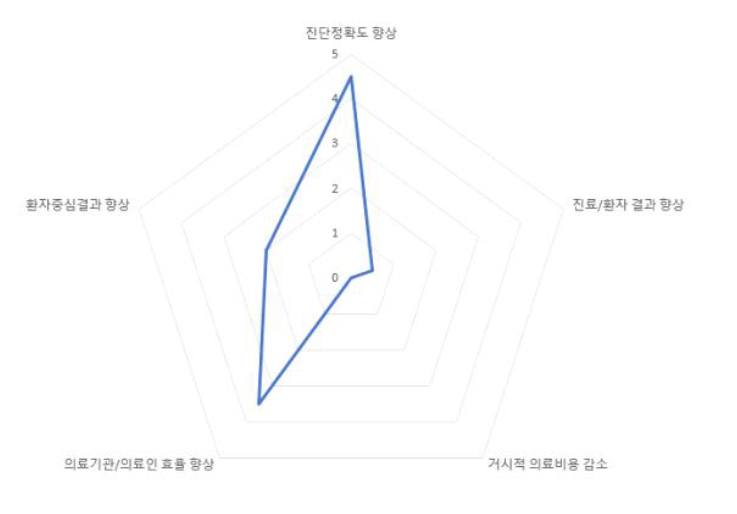
The rationale behind this decision is well articulated in Dr. Sung-Ho Park’s “Examples of Multidimensional Value Assessment of AI Medical Technologies.” In the case of report generation, while such tools may significantly improve physician and institutional efficiency, and—if performance is sufficiently high—may even enhance diagnostic accuracy, they are unlikely to directly improve patient outcomes or meaningfully reduce healthcare costs at a population level.
From a national payer’s perspective, there is therefore little justification for allocating additional financial resources to this category of technology. This is why report generation remains classified as Category A (existing reimbursement).
LLMs are great—I use them extensively myself. But just as no one uses a sashimi knife to cut schnitzel, even the best technology needs a precisely defined and appropriate use case.
Korean
CXR report generation에 대한 대한흉부영상의학회의 position statement가 나왔습니다.
결론적으로 말하면, 건강 검진(health screening) 세팅에서
Q1. AI 기반 판독문 생성의 신뢰도를 어느 정도로 믿을만하다고 하겠습니까?
Q4. 각 판독문이 영상의학과 의사에게 검증된다는 전제 하에 영상의학과가 있는 병원에서 사용하는 것이 적절합니까?
라는 두 질문에만 긍적적으로 컨센서스가 이뤄졌고, 나머지 모든 세팅과 모든 질문에 대해서는 긍정적인 컨센서스가 이뤄지지 않았습니다.
해당 position paper는 카카오의 KARA-CXR과 숨빗의 AIRead-CXR을 이용하여 흉부영상 전문의 20인들이 각자 본인 병원에서 가져온 60건의 CXR을 6가지 임상 환경(검진, 입원, 응급실, 중환자실, 호흡기 외래, 비호흡기 외래)에 대해서 평가하였습니다.
검진에서는 정확도가 약 86%로 우수한 성능을 보였지만, 이외의 환경에서는 60-69%의 정확도를 보이며 애매한 성능 지표를 보였습니다. 구체적인 데이터가 더 나와있지는 않은 것 같아서 검진의 low prevalence of diseases가 이러한 결과를 유도했는지는 모르겠지만, 일단 검진에서는 영상의학과의 검수 하에 이러한 report drafting tool을 쓰는 것이 가능은 하다는 입장을 확인할 수 있었습니다.
Anti-medical LLM 주의자 입장에서, 응당 그래야 할 것만 같은 입장을 대한흉영회에서 발표했다는 것이 반갑습니다. 잠깐 미국 이야기로 넘어가면, 챗지피티가 등장하고 3년이라는 시간이 더 지났지만 FDA의 인허가를 받은 LLM은 하나도 없습니다.
FDA에서 의료기기로 인허가를 받기 위해서는 중요한 두 가지가 필요합니다.
- IfU (Indications for Use) 어떤 사용 목적을 가지느냐? 이는 뇌졸중 검출 장치, 심박조율기 같이 명확하게 어디에 써야 한다는 목적이 있어야 한다는 말입니디. LLM처럼 온갖곳에 다 쓸 수 있는 의료기기는 IfU가 불명확하기 때문에 미국 의료기기 현행법상 의료기기로 인정을 받지 못하거나, LLM의 장점을 못 살리는 기기로 남을 수밖에 없습니다.
- 성능 검증의 이슈 생성형 모델은 텍스트(ex: 판독문)로 출력을 내놓곤 하는데 이를 제대로 검증할 수 있는 평가 지표가 없습니다. 영상의 판독문 문장을 의사와 똑같이 써야 100% 정확한 것일까요? 아니면 중요한 소견만 잘 찾으면 100% 정확하다고 할 수 있을까요? Normal variation까지 다 찾아야 정확한 것일까요? 한국의 경우에는 딥노이드의 M4CXR이 혁신의료기기를 받긴 했지만, 아직 보고서는 안나온 것 같습니다. 2019년에 초판, 2023년에 개정판이 나온 “혁신적 의료기술의 요양급여 여부 평가 가이드라인” 조차도 report generation을 Category A, 기존급여로 분류하고 있습니다. 돈 안주겠단 말이지요.
이는 박성호 선생님의 “AI 의료기술의 다면적 가치평가 예시집”에서 왜 돈 안주냐에 대한 논리적 근거를 찾아볼 수 있는데, report generation과 같은 경우에는 의료인/의료기관의 효율성 향상이 크고 (성능이 매우 좋은 경우에는) 진단정확도 향상을 꾀해 볼 수 있지만 환자의 예후를 좋아지게 만든다거나, 거시적으로 의료비용을 감소시킬 가능성은 상당히 낮기 때문에 국가 입장에서는 굳이 여기에 재원을 소모할 이유가 없습니다. 이러한 이유로 위 혁신의료기술 분류에서 Category A, 기존 급여에 해당하게 되는 것입니다.
LLM 좋죠, 저도 많이 씁니다. 근데 사시미로 돈까스를 써는 사람은 없는 것처럼 좋은 기술에도 딱 맞는 적절한 사용처가 있어야 하지 않나 싶습니다.