
수식이 깨지는 경우 다음 링크를 통해 접속하시면 됩니다.
이번 주에는 두 편의 논문 Estimation and Inference of Heterogeneous Treatment Effects using Random Forests와 이를 이용하여 의학 연구에 이용한 JAMA의 Heterogeneous Treatment Effects of Therapeutic-Dose Heparin in Patients Hospitalized for COVID-19 논문을 살펴 보겠습니다. 먼저는 Estimation and Inference of Heterogeneous Treatment Effects using Random Forests 논문부터 살펴보도록 하겠습니다.
Introduction
많은 경우에 우리는 어떤 요인이 대상들에게 어떻게 다르게 나타나는지 관심을 가지는 경우가 많습니다. 예를 들어, 특정 약이 특정 개인에게 효과가 있을지 여부, 정부 정책이 개개인에게 어떻게 다가올지의 여부, 그리고 A/B test와 같은 것들이 그러한 예시가 되겠지요. 현재까지 이어지는 통계학의 역사 속에서 randomized clinical trial (RCT)와 같은 것들은 control group과 treatment group들의 크기가 너무 커서 세부적인 subgroup들에 대한 통계적 유의한 효과 차이(heterogeneous treatment effect: HTE)를 보기가 쉽지 않았습니다. 하지만 최근에 와서야 causal inference라는 기법이 개발되며 이러한 것들을 조금이나마 가능케 만들어 주었습니다.
HTE에 대한 고전적 접근은 nearest-neighborhood matching, kernel method, series matching 같은 것들이 있었습니다. 이러한 방법들은 covariate의 개수가 적은 경우에는 잘 동작하지만 curse of dimension과 같은 이유 때문에 covariate의 개수가 증가하면 급격히 나쁜 성능을 보입니다.
본 연구에서는 random forest를 도구로 써서 causal inference를 수행하는 방식을 제안합니다. 이를 causal forest라고 부르겠습니다.
Causal Forests
Treatment Estimation with Unconfoundedness
Confounding factor, Confoundedness
어느 약의 효과를 추정하기 위해, 약에 대한 치료 효과를 측정하는 실험이 있다고 합시다. 그런데 알고 보니, 이 약은 성별에 따라서 효과가 다릅니다. 우리는 이러한 경우에, 성별이 약효의 confounding factor이라고 합니다. 즉, 도표로 그리면
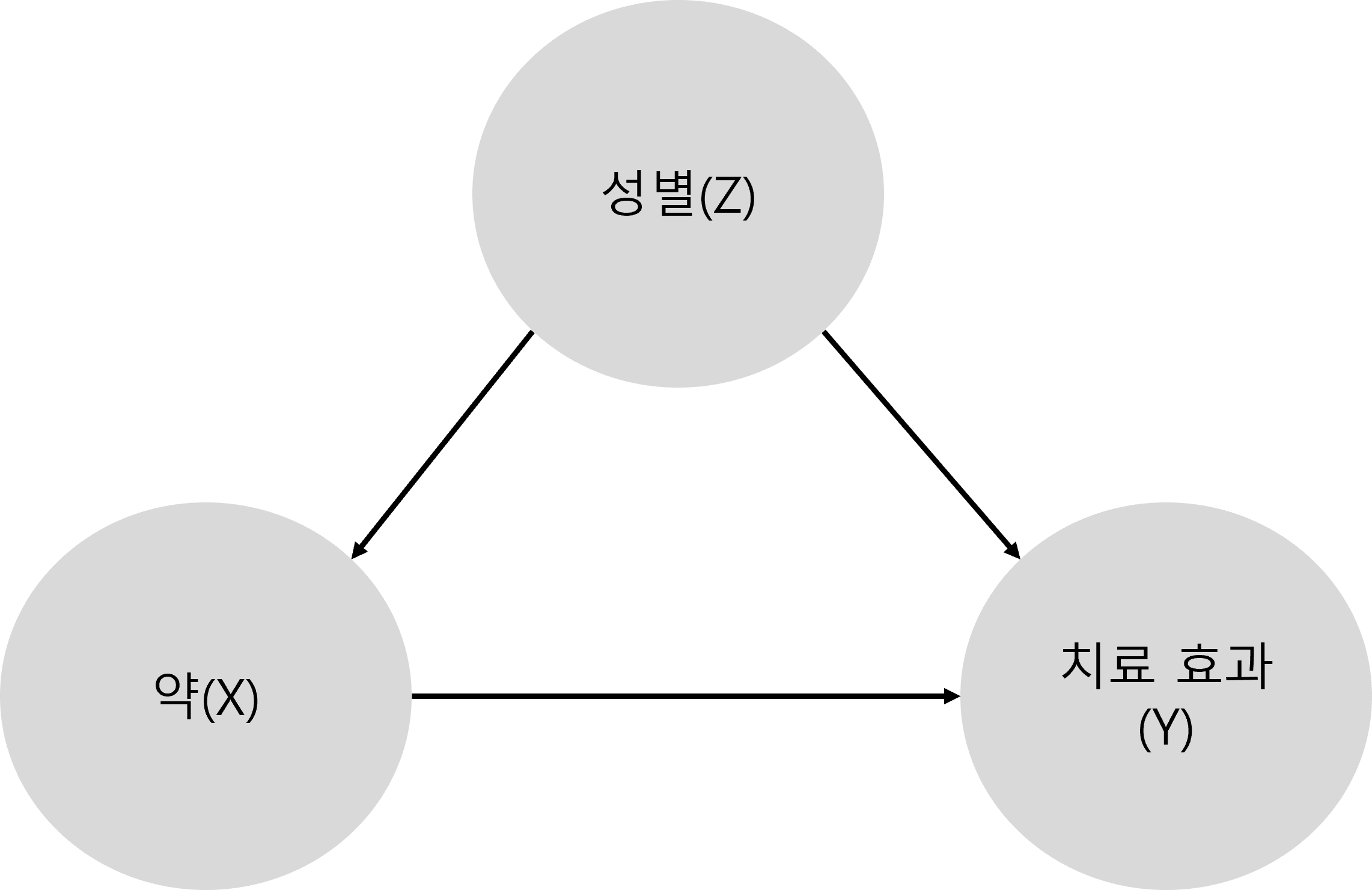
과 같은 모양이 될 것입니다. 다른 말로 하면, X에 따른 Y의 효과를 보려고 하는데 X와 Y에 모두 영향을 주는 변수 Z가 있으면 Z를 confounding factor이라고 하는 것이지요.
이제 본격적으로 들어가서, $n$개의 i.i.d training example들이 있다고 하고 이를 $i=1,\cdots,n$으로 labe합시다. 각 $i$번째 sample은 feature vector $X_i\in[0,1]^d$로 $d$개의 값을 0에서 1 사이로 갖는 변수라고 하고 response (=outcome) $Y_i$는 실수이며 treatment indicator, 즉 treatment를 받았는지 여부를 나타내주는 변수는 $W_i\in{0,1}$이라고 합시다. 그러면 치료를 받은 경우의 outcome을 $Y_i^{(1)}$, 치료를 받지 않은 경우의 outcome을 $Y_i^{(0)}$이라고 하고 treatment의 효과를
\[\tau(x)=\mathbb{E}\big[Y_i^{(1)}-Y_i^{(0)}\big|X_i=x\big]\]로 정의합시다. 위 식을 풀어 설명하면 치료를 받은 경우($Y_i^{(1)}$)에서 치료를 받지 않은 경우($Y_i^{(0)}$)를 각 개인마다 빼는 것으로 이해할 수 있습니다.
우리의 목적은 위 $\tau(x)$를 추정하는 것입니다. 사람마다 어떤 효과를 볼 지를 추정하는 것이지요. 하지만 문제가 있습니다. 어떤 사람이 치료를 받는 것과 치료를 받지 않는 것은 동시에 관찰할 수 없다는 것이지요. 결국, 치료를 받거나($Y_i^{(1)}$), 치료를 받지 않거나($Y_i^{(0)}$) 둘 중 하나만 관찰할 수 있다는 말입니다. 우리는 둘 중 하나를 관찰한 것을 사실(fact)라고 하고 관찰하지 못한 것을 반사실(counterfactual)이라고 부를 것입니다.
앞서 말한 이유 때문에 일반적으로 $\tau(x)$를 관찰된 데이터로부터 추정하는 것은 불가능합니다. 하지만, 몇 가지 가정을 끼워넣으면 제한된 상황에서는 가능해지기도 합니다. 바로 이 가정 중에 하나가 unconfoundedness입니다. Confounded가 아니라는 말이지요. 이는 treatment assignment $W_i$가 $X_i$가 주어진 경우 potential outcome $Y_i$와 독립이라는 가정이고 다음처럼 표기합니다:
\[\bigg\{Y_i^{(0)},Y_i^{(1)}\bigg\}\perp W_i\bigg| X_i\]이 unconfoundedness의 motivation은 randomized experiement입니다. 우리는 환자들을 random하게 배정하기 때문에 환자 정보가 주어졌다고 하더라도($X_i$), 치료 여부($W_i$)와 outcome($Y_i$)은 독립이라는 것을 가정할 수 있겠지요.
Unconfoundedness를 가정하면 우리는 다음과 같은 식 전개를 할 수 있습니다:
\[\begin{align*}\tau(x)&=\mathbb{E}\big[Y_i^{(1)}-Y_i^{(0)}\big|X_i=x\big]\\ &=\mathbb{E}\big[Y_i^{(1)}\big|X_i=x\big]-\mathbb{E}\big[Y_i^{(0)}\big|X_i=x\big]\\ &=\mathbb{E}\big[Y_i^{(1)}\big|X_i=x\big]\frac{e(x)}{e(x)}-\mathbb{E}\big[Y_i^{(0)}\big|X_i=x\big]\frac{1-e(x)}{1-e(x)}\\ &=\mathbb{E}\big[Y_i^{(1)}\big|X_i=x\big]\frac{\mathbb{E}[W_i|X_i=x]}{e(x)}-\mathbb{E}\big[Y_i^{(0)}\big|X_i=x\big]\frac{\mathbb{E}[1-W_i|X_i=x]}{1-e(x)}\\ &=\mathbb{E}\bigg[\frac{Y_i^{(1)}W_i}{e(x)}-\frac{Y^{(0)}(1-W_i)}{1-e(x)}\bigg|X_i=x\bigg]\\ &=\mathbb{E}\bigg[Y_i\bigg(\frac{W_i}{e(x)}-\frac{1-W_i}{1-e(x)}\bigg)\bigg|X_i=x\bigg] \end{align*}\]마지막 두 줄은 $W_i$가 indicator 역할을 하기 때문에 성립합니다. $W_i$에 0과 1을 한 번씩 대입해서 전개해 보세요.
이 식은 사실 $x$라는 특성을 가진 환자가 treatment를 받는 propensity입니다. 따라서 $e(x)$를 알게 된다면 $\tau(x)$라는 unbiased estimator을 알게 되는 것입니다. 많은 논문들에서는 $e(x)$를 추정하여 $\tau(x)$를 알아내는 방식을 취했지만, 본 논문에서는 더 indirect한 방법을 취합니다.
From Regressioin Trees to Causal Trees and Forests
머신러닝을 공부해 본 사람이라면 tree와 forest가 adaptive neighborhood metric을 통한 nearest neighborhood method임을 직관적으로 알고 있을 것입니다. 본 section의 내용은 이를 변형한 것입니다.
먼저 우리가 independent sample들 $(X_i, Y_i)$들만을 관찰하고 CART regression tree를 만들고 싶다고 합시다. 그렇다면 우리는 feature space를 leave $L$을 찾을 때까지 재귀적으로 split 할 것입니다. 이후에 test sample $x$가 주어졌다고 하면 $x$를 포함하는 leaf $L(x)$를 밝혀냄으로 prediction $\hat{\mu}(x)$를 계산할 것입니다:
\[\hat{\mu}(x)=\frac{1}{|\{i:X_i\in L(x)\}|}\sum_{\{i:X_i\in L(x)\}}Y_i\]Causal tree 관점에서 우리는 leaf들로부터의 treatment effect를
\[\hat{\tau}(x)=\bigg(\frac{1}{|\{i:W_i=1,X_i\in L(x)\}|}\sum_{\{i:W_i=1,X_i\in L(x)\}}Y_i\bigg) - \bigg(\frac{1}{|\{i:W_i=0,X_i\in L(x)\}|}\sum_{\{i:W_i=0,X_i\in L(x)\}}Y_i\bigg)\]로 아주 간단하게 추정할 것입니다.
최종적으로, single causal tree를 생성하는 procedure이 주어졌다고 하고 총 tree의 개수를 $B$, 각 tree를 $b$라고 하면 estimate들은 각각 $\hat{\tau}b(x)$가 될 것입니다. 이후에는 최종 output을 $\hat{\tau}(x)=B^{-1}\sum{b=1}^B\hat{\tau}_b(x)$로 정의하는 것이 상식적이죠.
Theoretical Analysis
이론적인 설명은 생략하도록 하겠습니다(절대 제가 이해못해서 그러는건 아닙니다.). 너무 복잡뇌절하기도 하고, 알고리즘의 깊은 이해에는 도움이 되겠지만 실용적인 측면에서는 도움이 되지 않는다는 판단입니다.
Algorithms
Double-Sample Trees
Double sample tree들은 training data를 두 부분으로 나눕니다: 절반은 각 leaf 안에서 우리가 원하는 response를 예측하는 모델을 학습하는데 쓰이는 데이터이고, 다른 절반은 split을 만드는데 쓰입니다.
- Input : $n$개의 training example로, $(X_i,Y_i)$의 꼴을 띄고 있는 regression tree이거나 $(X_i,Y_i,W_i)$의 꼴을 띄고 있는 causal tree로, notation은 위에 설명한 notation을 따릅니다.
Algorithm
비복원추출로 $n$개의 sample 중 $s$개의 샘플을 선택해서, 이를 $ \mathcal{I} =\lfloor s/2\rfloor$라는 집합 하나와 $ \mathcal{J} =\lceil s/2\rceil$로 나눕니다. - Recursive partitioning을 통해 tree를 만듭니다. Split은 $\mathcal{J}$ sample로부터 아무 데이터나 추출하고 $\mathcal{I}$ sample의 $X$와 $W$ sample들을 아무렇게나 추출하여 선택되지만 $\mathcal{I}$ sample의 $Y$ observation은 사용하지 않습ㄴ디ㅏ.
- $\mathcal{I}$ sample의 $Y$ observation을 통해 leaf-wise response를 estimate합니다.
- Double sample regression tree와 double sample causal tree가 다른 점은 $\hat{\mu}(x)$를 추정하느냐, $\hat{\tau}(x)$를 추정하느냐 그 차이밖에 없습니다.
Propensity Trees
Propensity tree들은 treatment assignment indicator $W_i$만을 사용하여 split을 만들어냅니다.
- Input : $n$개의 training example로, $(X_i,Y_i)$의 꼴을 띄고 있는 regression tree이거나 $(X_i,Y_i,W_i)$의 꼴을 띄고 있는 causal tree로, notation은 위에 설명한 notation을 따릅니다. Minimum leaf size는 $k$입니다.
Algorithm
- 비복원추출로 size $s$인 random subsample $\mathcal{I}$를 추출합니다.
- Outcome이 treatment assignment $W_i$인 classification tree를 sample $\mathcal{I}$를 사용하여 학습합니다. 각 leaf는 각 treatment class마다 $k$개 이상의 observation을 가져야 합니다.
- $\tau(x)$를 estimate합니다.
마치며
이번 글에서는 HTE를 random forest로 추정하는 causal forest를 살펴보았습니다. 다음 글에서는 이것이 구체적으로 어떻게 의료에 적용되는지 살펴보겠습니다.